
AI 搶灘陣式1:加強定義問題能力&前瞻基礎研究
AI 大潮逼近!瀟灑沖浪或……狼狽滅頂?
AI 大潮逼近!瀟灑沖浪或……狼狽滅頂?
人工智能 (AI) 狂潮來襲,有人盲從跟風、見獵心喜,也有人視若洪水猛獸,愁腸百結;關于強/弱 AI 的道德爭議、軟/硬計算技術、實用性、與人類競合矛盾的辯證不絕于耳,對于 CPU (中央處理器)、GPU (圖形處理器),乃至不斷推陳出新的各式特定應用集成電路 (ASIC)——APU (加速處理器)、VPU (視覺處理器)、TPU (張量處理器),以及可編程邏輯門陣列 (FPGA) 的討論亦不斷躍上版面。在走馬看花眾多演進史、產品規格與零散案例后,有志屹立 AI 浪頭的開發者在實際應用時,到底該考慮哪些面向并選擇符合所需的組件?
GPU 以"浮點計算"名動江湖
CPU 是由計算邏輯單元 (ALU)、內存和控制器所組成,可一力完成訊號處理、指令編碼、發號施令等動作;然而在訊號鏈傳遞的過程中,若事無輕重緩急皆由 CPU 出面,未免不夠"知人善任"。為加速繁雜且重復性高的數據處理 (如:影像圖文件),人們變通地將 IC 大部分的晶體管挪給超大數組 ALU 做并行計算,因而促成 GPU 興起。若將整個 IC 資源分配用人類大腦潛能開發模擬,有人善于思考、決策,一如 CPU;有人精于邏輯推理、就像 GPU,在"高精度浮點計算"尤其相形見長。因此,若將兩者硬性比較,似乎有失公允。
CPU 是由計算邏輯單元 (ALU)、內存和控制器所組成,可一力完成訊號處理、指令編碼、發號施令等動作;然而在訊號鏈傳遞的過程中,若事無輕重緩急皆由 CPU 出面,未免不夠"知人善任"。為加速繁雜且重復性高的數據處理 (如:影像圖文件),人們變通地將 IC 大部分的晶體管挪給超大數組 ALU 做并行計算,因而促成 GPU 興起。若將整個 IC 資源分配用人類大腦潛能開發模擬,有人善于思考、決策,一如 CPU;有人精于邏輯推理、就像 GPU,在"高精度浮點計算"尤其相形見長。因此,若將兩者硬性比較,似乎有失公允。
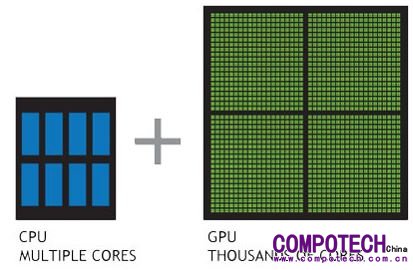
圖1:CPU 含有數顆內核,適用于為循序的序列處理優化;GPU 含有數千個更小型且高效率的內核,適用于同時處理多重任務
數據源:http://www.nvidia.com.tw/object/what-is-gpu-computing-tw.html
近年拜 AI 遍地開花之賜,讓 GPU 忽集萬千寵愛于一身,目前已有超過 2,000 家的 AI 新創公司建構于龍頭廠商英偉達 (NVIDIA) 的產品之上,連帶使其身價暴漲。眼見 GPU 風華正茂,英特爾 (Intel) 與超威 (AMD) 也著手開發新一代指令集以提升 CPU 的浮點計算能力;前者于近期正式發布業界首款"類神經網絡處理器"(NNP)——Nervana,省略標準高速緩存 (Cache)、避免記憶不同步、須清除快取的麻煩,以提高計算效率,后者在收購 ATi 公司后啟動"Fusion"項目,欲借助"異質系統架構"(HSA) 的 APU,以 CPU+GPU"二打一"之姿奮力一搏。
APU 最大特點為:使用 HyperTransport (HT) 總線將 CPU 和 GPU 兩個不同計算架構整合在同一個 IC 上,使其協同運作;開發人員可通過免權利金 OpenCL (開放計算語言) 的應用程序編程接口 (API),加速 CPU、GPU 和 APU 進程。APU 的最終目標是:將 CPU 與 GPU"完全融合",根據任務類別自動分派計算任務,以降低設備的功耗和發熱。特別一提的是,AMD 于 2007 年發布的 SSE5 指令集,已意外被 Intel 吸收、優化為"乘法及加法融合指令"(Fused Multiply-Add, FMA),以簡化計算步驟、使浮點計算的峰值倍增。
VPU、TPU 為"特定應用"分眾市場而生
VPU 主要專注于影像計算、不須負責輸出或處理其它應用,旨在作為特定 AI 工作的獨立加速器或"推論"(inference) 引擎,頗具"特務"意味;真正捧紅 VPU 一詞的推手,當屬電腦視覺芯片先驅 Movidius 公司。Movidius Myriad 2 VPU 芯片組已獲聯想 (Lenovo) 虛擬現實 (VR) 產品采用,而 Google 也承諾用它作為平臺的神經計算引擎,增進移動設備的機器學習能力。2016 年 9 月收歸 Intel 旗下后,今年更為大疆創新科技的首款迷你無人機 Spark 加強物體檢測、實現 3D 制圖和基于深度學習算法的環境感知。
VPU 主要專注于影像計算、不須負責輸出或處理其它應用,旨在作為特定 AI 工作的獨立加速器或"推論"(inference) 引擎,頗具"特務"意味;真正捧紅 VPU 一詞的推手,當屬電腦視覺芯片先驅 Movidius 公司。Movidius Myriad 2 VPU 芯片組已獲聯想 (Lenovo) 虛擬現實 (VR) 產品采用,而 Google 也承諾用它作為平臺的神經計算引擎,增進移動設備的機器學習能力。2016 年 9 月收歸 Intel 旗下后,今年更為大疆創新科技的首款迷你無人機 Spark 加強物體檢測、實現 3D 制圖和基于深度學習算法的環境感知。
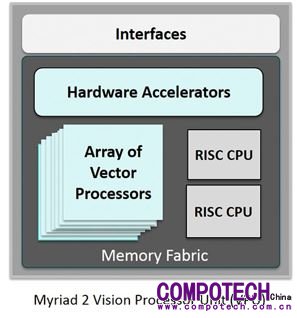
隨后,Intel 又陸續推出內建 Movidius Myriad 2 VPU 的神經計算棒 (NCS) 與 Myriad X VPU 系統單芯片 (SoC)——前者每秒超過千億次浮點計算可實時執行深度神經網絡 (DNN);后者要求"全球首個配備專用神經網絡計算引擎的 SoC"。同樣看好圖像處理商機,日商索思未來 (Socionext) 亦搶在今年初發表首款符合 OpenVX 開放 API 標準的圖像顯示控制器暨加速器 SC1810,內建專利 VPU 除配有 OpenVX 硬件加速器,還具備可編程數據并行加速器;免授權金的 API 及專屬 VPU、H.264 編譯碼器,可降低嵌入環景監控、物體偵測等視覺功能成本。
TPU 是 Google 針對自家開源深度學習框架 TensorFlow 所發展的 ASIC,兼具 CPU、GPU 可編程優點,能在不同網絡模型執行復雜指令集 (CISC),在深度學習 (Deep Learning) 的"推論",擁有更好的"單位功耗效能"。即使個別浮點計算能力不如 GPU,但團結力量大,今年發布的第二代 TPU2 (又稱 Cloud TPU) 集成四個 16 位處理器,每組效能達 180 TFLOPS (TeraFLOPS);現已布署在 Google Compute Engine 平臺上,與 CPU、GPU 協作加速。若將 64 個 TPU2 串聯升級為"TPU Pods"超級電腦,效能更上看 11.5 PFlops (PeraFLOPS)。
"靈活"是 FPGA 最大優勢,異質計算蓄勢起飛
上述一眾 ASIC 產品,都是電路布局既定的硬件系統;但嚴格來說,用于圖像處理 (訓練) 及統計計算 (推論) 的技術要求仍有些許差異。若想要用一塊電路板靈活滿足兩種需求,就得為開發人員保留部分編程空間,于是,類似"半成品"的 FPGA,因為可一舉解決全定制電路的不足與 FPGA 邏輯閘電路有限的缺憾,也趁勢搭上這波 AI 順風車。開發人員可運用 Verilog 或 VHDL 等硬件描述語言定義邏輯電路,根據當下需要快速布線、連接內部邏輯區塊后,再刻錄至 FPGA;惟因指令周期有限、功耗相對大,無法因應過于復雜的設計。
上述一眾 ASIC 產品,都是電路布局既定的硬件系統;但嚴格來說,用于圖像處理 (訓練) 及統計計算 (推論) 的技術要求仍有些許差異。若想要用一塊電路板靈活滿足兩種需求,就得為開發人員保留部分編程空間,于是,類似"半成品"的 FPGA,因為可一舉解決全定制電路的不足與 FPGA 邏輯閘電路有限的缺憾,也趁勢搭上這波 AI 順風車。開發人員可運用 Verilog 或 VHDL 等硬件描述語言定義邏輯電路,根據當下需要快速布線、連接內部邏輯區塊后,再刻錄至 FPGA;惟因指令周期有限、功耗相對大,無法因應過于復雜的設計。

圖3:零度科技 (Zerotech) 的只有口袋大小的無人機 Dobby AI,采用 Xilinx Zynq Z-7020 SoC 運作深度學習功能偵測人的手勢
數據源:https://forums.xilinx.com/t5/Xcell-Daily-Blog/Zerotech-s-palm-sized-Dobby-AI-drone-uses-DeePhi-machine/ba-p/774764
賽靈思 (Xilinx) 繼今年 3 月在 2017 嵌入式世界大會上展示視覺導向智能系統后,5 月更宣布投資專精于深度壓縮、編譯工具鏈,以及系統層級優化的機器學習應用領域的深鑒科技公司,擬推出各種從終端到云端的推論平臺。整體論之,FPGA 適用于初期出貨量偏小的產品或供原型設計驗證之用,Cadence、Synopsys 等電子設計自動化 (EDA) 供貨商亦積極提供相關解決方案;以 NVIDIA 為首的 GPU 受惠于先天的并行計算架構,格外適合捕捉"瞬間"的高效計算 (HPC);但欲將 AI 進階到"人腦決策",CPU 亦須與時俱進、加入協作行列。
另一方面,AMD 正快馬加鞭沖刺 AMD Radeon Instinct GPU 加速器,加上自有 x86 CPU 專利、鎖定服務器開發的多內核 EPYC 處理器加持,是否能讓"異質融合計算"再上一層樓、與 Intel、NVIDIA 一爭長短?值得關注。此外,由于多數機器學習不需從 cache 讀取數據,若數據源高度本地化、側重就地執行的專職應用,則 VPU、TPU 等"術業有專攻"的分眾 ASIC,更便于"挑重點"嵌入、集中火力專攻某一項職能——這也是為何 AlphaGo 從 CPU+GPU 架構轉成 TPU 后,對弈實力如秋風掃落葉、大獲全勝之故。
AI 要能付諸實際應用,才有獲利機會
事實上,系統商自行開發的 ASSP 預估有增多趨勢,也是眾家硅智財暨 EDA 工具商所念茲在茲、殷切期盼的潛力市場;例如,微軟 (Microsoft) 的擴增實境 (AR) 顯示器 HoloLens,即內建"全像處理器"(Holographic Processing Unit, HPU)。歸根結底,我們究竟要如何在這波滔天巨浪中安身立命?誠如波士頓顧問公司 (BCG) 合伙人暨董事總經理徐瑞廷日前在《2017 arm 科技論壇高峰座談會》中所提及:"時至今日,光談技術及對行業的影響是不夠的,如何落實到應用層面才重要,而不同應用場景的使用案例 (Use Case) 更是焦點。"
事實上,系統商自行開發的 ASSP 預估有增多趨勢,也是眾家硅智財暨 EDA 工具商所念茲在茲、殷切期盼的潛力市場;例如,微軟 (Microsoft) 的擴增實境 (AR) 顯示器 HoloLens,即內建"全像處理器"(Holographic Processing Unit, HPU)。歸根結底,我們究竟要如何在這波滔天巨浪中安身立命?誠如波士頓顧問公司 (BCG) 合伙人暨董事總經理徐瑞廷日前在《2017 arm 科技論壇高峰座談會》中所提及:"時至今日,光談技術及對行業的影響是不夠的,如何落實到應用層面才重要,而不同應用場景的使用案例 (Use Case) 更是焦點。"

照片人物:BCG 合伙人暨董事總經理徐瑞廷
徐瑞廷表示,如果不能了解終端用戶怎么應用產品,今后將很難使得上力。除了商業模式的改變、滿足客戶對產品規格的需求并降低成本外,還須考慮到與不同生態系的伙伴合作。企業內部也要重新思考組織策略,不是只有賣產品、而是要更深入理解客戶,故人才需求也不同;從銷售單一組件、產品到整體解決方案,既有員工能力未必跟得上。為獲取新能量,導致投資并購、企業轉型與是否引入新血的議題十分熱烈,例如,日本某家傳感器廠商為取得終端資料便成立顧問團隊,改以"提升良率"為賣點。

圖4:DynamIQ 是 arm Cortex-A CPU 的新技術,通過在集群 (Cluster) 內部集成智能電源來提高 AI 計算能源效率
數據源:https://community.arm.com/processors/b/blog/posts/arm-dynamiq-technology-for-the-next-era-of-compute




